
人类秒懂,AI却懵圈:VLM²
作者:admin日期:2025/03/15 浏览:
 本文来自港科与 MIT 教学团队。本文有两个独特一作:张鉴殊为武汉年夜学本科四年级,本篇为其在港科年夜拜访时期实现,将于 2025 春季前去美国东南年夜学攻读 CS PhD。姚栋宇现在就读于 CMU CS 系下的 MSCV 名目。
本文来自港科与 MIT 教学团队。本文有两个独特一作:张鉴殊为武汉年夜学本科四年级,本篇为其在港科年夜拜访时期实现,将于 2025 春季前去美国东南年夜学攻读 CS PhD。姚栋宇现在就读于 CMU CS 系下的 MSCV 名目。 论文链接:https://arxiv.org/pdf/2502.12084名目主页:https://vlm2-bench.github.io/以后,视觉言语模子(VLMs)的才能界限一直被冲破,但年夜少数评测基准仍聚焦于庞杂常识推理或专业场景。本文提出全新视角:假如一项才能对人类而言是 “无需思考” 的天性,但对 AI 倒是宏大挑衅,它能否才是 VLMs 亟待冲破的中心瓶颈?基于此,该团队推出 VLM²-Bench 来体系探索模子在 “人类级基本视觉线索关系才能” 上的表示。本文将如下的两点作为本任务的动身点:什么才能对人类来说是在一样平常生涯中十分主要,且这种才能还得是对人们来说十分轻易的,不须要宏大的常识贮备也能实现。咱们在阅读差别的照片时能够找到呈现在多张照片的统一团体,然而咱们并不须要在之前就见过这团体,叫得闻名字或许对这团体很懂得,而是简略的在差别的图片间经由过程脸部特点在视觉上的比对跟关系。同理咱们还会拿着爱好球鞋的图片去线下门店比对筛选出一样的格式(如下图),而不须要晓得这个鞋的详细产物型号,只要要把鞋的斑纹这一视觉特点给关系起来即可。这种视觉关系的才能显然是不依附于先验常识,是纯洁基于视觉侧的关系。
论文链接:https://arxiv.org/pdf/2502.12084名目主页:https://vlm2-bench.github.io/以后,视觉言语模子(VLMs)的才能界限一直被冲破,但年夜少数评测基准仍聚焦于庞杂常识推理或专业场景。本文提出全新视角:假如一项才能对人类而言是 “无需思考” 的天性,但对 AI 倒是宏大挑衅,它能否才是 VLMs 亟待冲破的中心瓶颈?基于此,该团队推出 VLM²-Bench 来体系探索模子在 “人类级基本视觉线索关系才能” 上的表示。本文将如下的两点作为本任务的动身点:什么才能对人类来说是在一样平常生涯中十分主要,且这种才能还得是对人们来说十分轻易的,不须要宏大的常识贮备也能实现。咱们在阅读差别的照片时能够找到呈现在多张照片的统一团体,然而咱们并不须要在之前就见过这团体,叫得闻名字或许对这团体很懂得,而是简略的在差别的图片间经由过程脸部特点在视觉上的比对跟关系。同理咱们还会拿着爱好球鞋的图片去线下门店比对筛选出一样的格式(如下图),而不须要晓得这个鞋的详细产物型号,只要要把鞋的斑纹这一视觉特点给关系起来即可。这种视觉关系的才能显然是不依附于先验常识,是纯洁基于视觉侧的关系。 一样平常生涯中咱们常常应用“视觉关系”,比方图中这个男孩正拿动手机上的图片去线下门店逐一比对,来筛选出一样的球鞋格式(图片由AI天生)为什么这种才能对当初 VLMs 也长短常主要的?跟着 VLMs 从单图处置扩大到多图、视频输入,其视觉感知的广度跟深度明显晋升。但是,视觉内容的扩大并未带来对视188体育APP觉线索关系才能的同步晋升,而 VLMs 时须要存在 “回首” 关系视觉线索的才能来辅助在其更分歧且跟谐的懂得天下。VLM²-Bench 的计划
一样平常生涯中咱们常常应用“视觉关系”,比方图中这个男孩正拿动手机上的图片去线下门店逐一比对,来筛选出一样的球鞋格式(图片由AI天生)为什么这种才能对当初 VLMs 也长短常主要的?跟着 VLMs 从单图处置扩大到多图、视频输入,其视觉感知的广度跟深度明显晋升。但是,视觉内容的扩大并未带来对视188体育APP觉线索关系才能的同步晋升,而 VLMs 时须要存在 “回首” 关系视觉线索的才能来辅助在其更分歧且跟谐的懂得天下。VLM²-Bench 的计划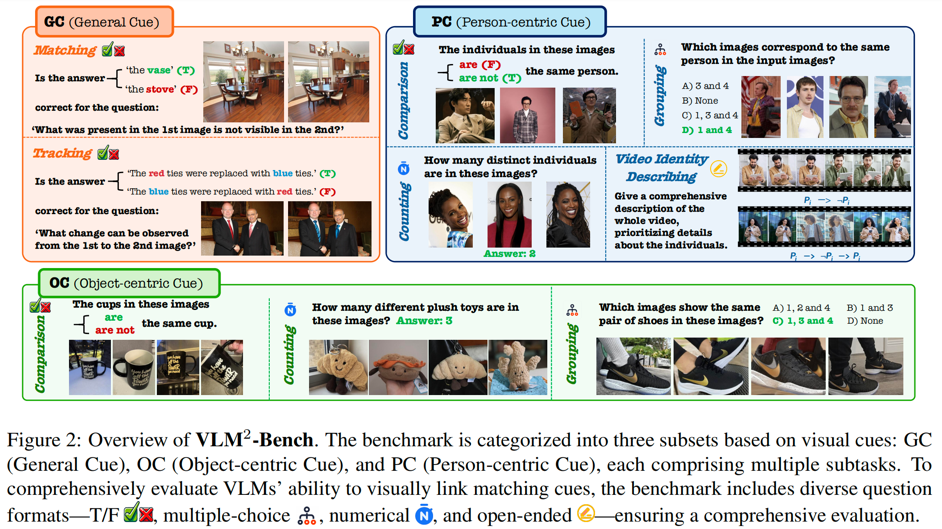 片面考核 VLMs 对通用线索 GC(General Cue)、物体线索 OC(Object-ce188bet官网ntric Cue)跟人物线索 PC(Person-centric Cue)三个年夜类的基本关系才能,统共可分为 9 个子义务,同时涵盖多图跟视频的测试数据,合计 3060 个测试案例。评测成绩的情势包括了断定题、多选题、数值题、开放题,此中对每种情势咱们都计划了特定的评价方法来更好的反映模子的机能。联合人工验证与主动化过滤,同时确保数据品质与挑衅性。
片面考核 VLMs 对通用线索 GC(General Cue)、物体线索 OC(Object-ce188bet官网ntric Cue)跟人物线索 PC(Person-centric Cue)三个年夜类的基本关系才能,统共可分为 9 个子义务,同时涵盖多图跟视频的测试数据,合计 3060 个测试案例。评测成绩的情势包括了断定题、多选题、数值题、开放题,此中对每种情势咱们都计划了特定的评价方法来更好的反映模子的机能。联合人工验证与主动化过滤,同时确保数据品质与挑衅性。 相关文章
- 2025/03/151
- 2025/03/14单机多人游戏哪个好 最热单机多人游戏排
- 2025/03/14情境游戏下载 最新情境游戏清点
- 2025/03/13剧集游戏哪个好 人气高的剧集游戏推举
- 2025/03/13若何在酷热的夏日坚持汽车前摄像头的热

 客户经理
客户经理